
This is based on a ServiceNow AI Academy video: “Configure and Solve – Deploy AI Agents with confidence using Agentic Evaluations”
https://www.youtube.com/watch?v=15Z3KgzMZq8
DISCLAIMER: I don’t claim any merit for what follows. This is simply my own summary and interpretation after watching the video — rephrased, reorganized, and mixed with a some personal reflections. I mostly do this for myself, to keep learning and to have a structured reference I can revisit later.
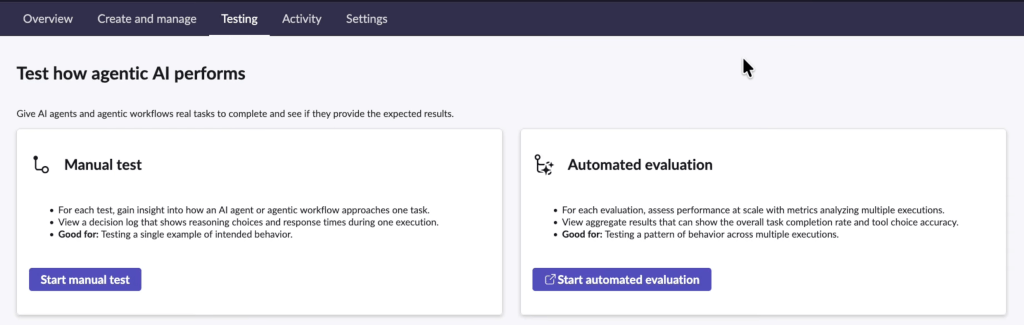
The idea is simple: once I built an agentic workflow, manual testing is not enough. I also need automated evaluation at scale.
This is needed because AI agents are probabilistic systems, not deterministic software: issues don’t show up as single test pass/fail, but as trends over large volume.
It’s like a plane leaving Los Angeles for Boston. If it’s off by just a degree, nothing can be perceived at takeoff. But over distance, that tiny deviation compounds — and I land in Washington instead.
AI agents are similar. A small behavioral drift may not be perceived in a few tests. At scale, it quietly moves me away from the intended outcome.
In a traditional ServiceNow configuration, if a business rule works once, it will work the same way every time — assuming the inputs remain consistent. The system is predictable by design.
An AI agent is not. It interprets, reasons, selects tools, and generates responses based on probabilities. Subtle variations in input, data, model interpretation can produce differences in behavior.
As Alway, manual testing is a pre-requisite to eliminate obvious defects. Automated evaluation is the second level of testing to reveal variance at large scale, close to real life, where insidious risk reside and harms.
3 pillars of AI agent Evaluation
- The agent
- The metrics
- The dataset
The agent
I select the agent or agentic workflow I want to evaluate. I can name the evaluation, describe it, and choose which version of the agent to assess.

With deterministic workflows, I can often reason through the impact of a change. With AI agents, small prompt adjustments or tool description tweaks can alter behaviour in ways that are difficult to anticipate.
But evaluation only is valuable if it is systematic. If it remains a one-time activity before go-live, it will quickly lose relevance, as the LLM or data set evolves. I
Ideally, this should sit in the lifecycle — part of controlled releases, not a demo exercise.
The metrics
ServiceNow provides three out-of-the-box metrics, powered by LLM judges:
- Overall task completeness => Did the agent complete the task?
- Tool choice evaluation => Did it choose the correct tools/skills?
- Tool calling evaluation => Did it call them correctly? (passing the right vaviabes?)

It focuses on execution mechanics. These metrics primarily assess procedural correctness. They verify that the agent followed a coherent path and used platform capabilities as expected.
They do not validate business relevance of the outcome. An agent might:
- Retrieve an incident correctly
- Select the update tool
- Pass valid parameters
- Complete all required steps
And still assign an inappropriate category. From a process perspective, it succeeded. From a business perspective, it may have failed.
Also, it doesn’t evaluate if the skills the agentic workflow is using are sound. If a correct flow is called by the agent, but the flow logic is poorly configured, the agent will be satisfied, but the result won’t good. To be fair, it’s probably something I should find out at unit testing.
The judge — itself an AI model — evaluates execution logs and produces scores and natural language justifications. This is helpful for diagnosing configuration issues, but it is not a guarantee of truth. The judge itself can be corrupted and biased. It is an automated reviewer operating within defined assumptions.
That is OK as long as we remain clear about what is being measured.
The dataset
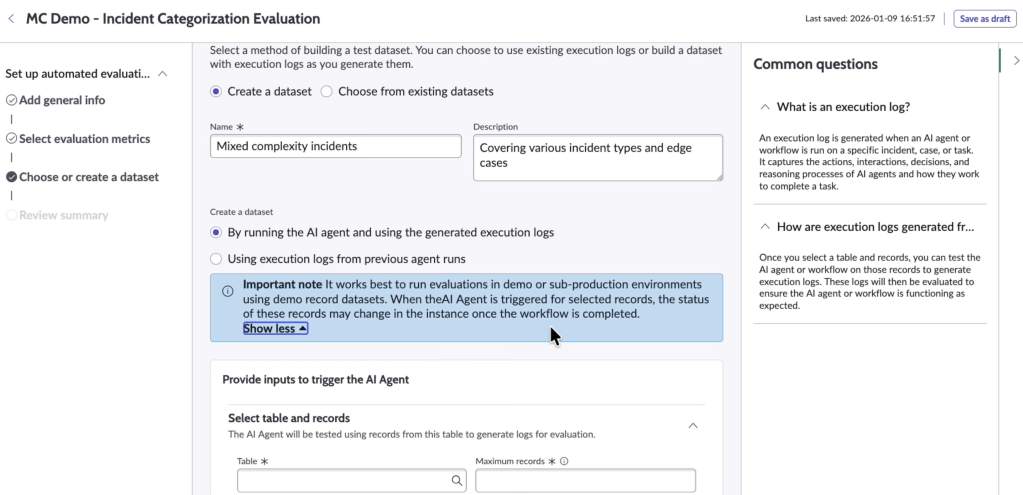
Do not select only recent or easy cases. The goal is to simulate real life chaos. Hence, include:
- Edge cases (outliers weirs ones)
- Incidents with unusual descriptions
- Cases with missing fields
- False positives
- True negatives
A small, clean dataset can produce excellent scores. But production reality is rarely clean
Think about video games at launch: before release, professional testers spend months validating gameplay. They run structured scripts. They simulate edge cases they can anticipate. The game appears stable.
Then the game goes live. Millions of players connect. Within hours, someone discovers that if I jump backwards, switch weapons mid-air, and disconnect the controller, I can walk through walls.
No professional tester would reasonably attempt that sequence. Not because they lack skill, but because human imagination is limited. Collective imagination at scale is not.
Thousands of users phrase requests in unexpected ways. They omit fields. They mix languages. They copy-paste log files full of noise. They contradict themselves. They escalate emotionally. They repeat actions in odd sequences.
Suddenly, combinations of inputs appear that were never tested together. The agent doesn’t “crash.” It simply reacts in ways I didn’t anticipate.
Unit tests validate what I can imagine. Evaluation at scale exposes what I couldn’t.
Running the evaluation
Technically, the platform simulates executions across selected scenarios, then judges evaluates the logs. An AI conversational partner interacts with the agent, mimicking a user.
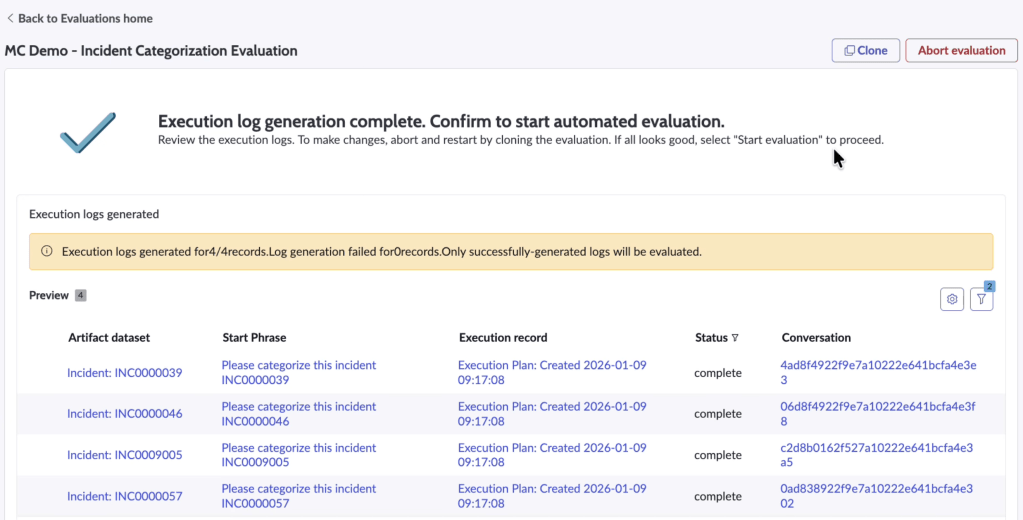
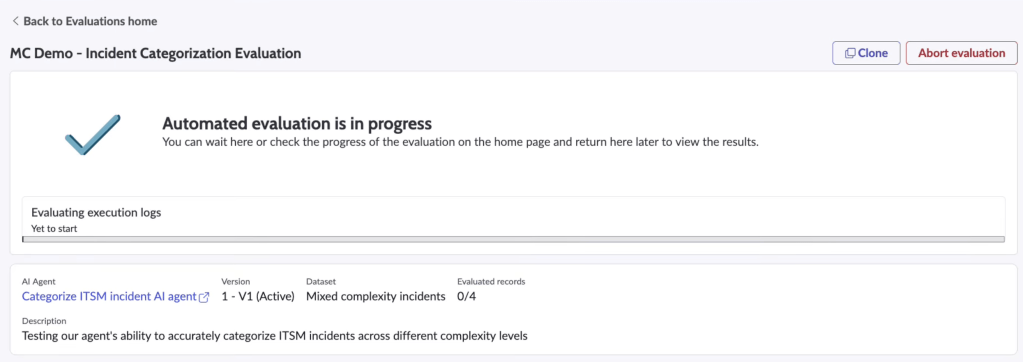
Results are presented in two views:
- Overview: aggregate performance, deployment readiness indicator
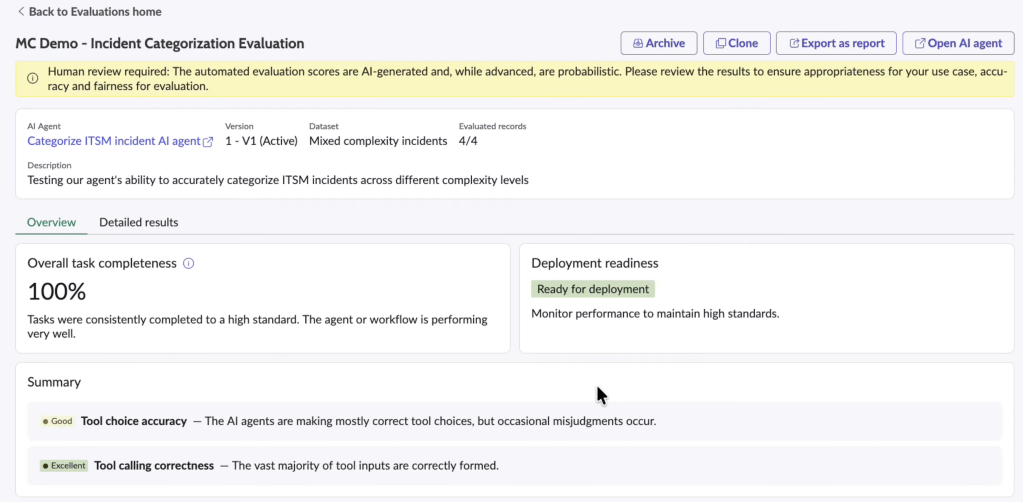
- Detailed results: record-level breakdown, per-metric scoring, justifications
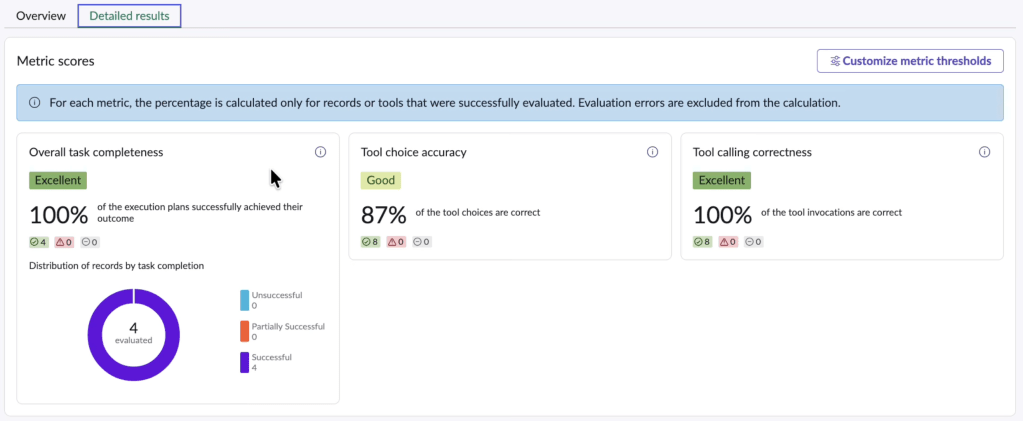
Scores are basic like: 3 = successful, 2 = partially successful, 1 = failed and score thresholds are configurable.

An “Excellent” rating means the agent behaved correctly across the dataset I selected, under the thresholds I defined.
A three-point scale is OK to start, but it does not tell me whether failures cluster around a specific category. It does not tell me whether misclassifications occur in high-risk cases, so I still need a detailed anaysis.
Use case demonstrated – Incident categorization —too familiar
The demo focuses on incident categorization.
The “Incident categorization” use case comes up in AI demos since Predictive intelligence since 2017 (9 years ago). It’s easy to understand but I admit there is a bit of fatigue with that use case.
Re-using that again and again reveals we haven’t figured that out yet. Also, the auto-categorization, can be achieved with or without AI Agents, so it doesn’t illustrate the unique edge that capability offers.
The agent can reason through context, select tools dynamically, and update records without rigid scripting. That flexibility introduces variability.
In deterministic flows, I control every branch and the result is the direct consequence of my changes. In agentic flows, I define intent and guardrails — the rest is inference. Evaluation becomes the safety net.
Closing comments
Wrap up configuration and evaluation flow:
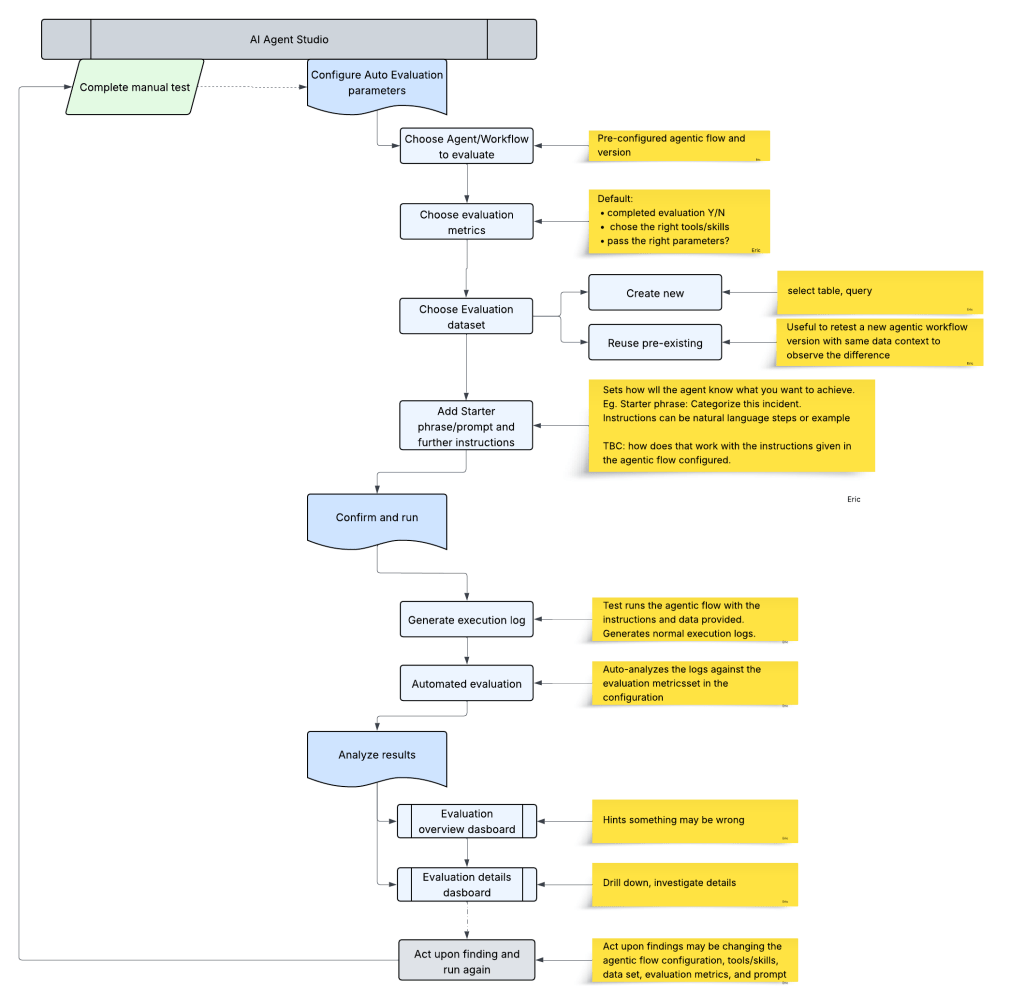
Agentic evaluations is not without reminding me of Automated Test Framework (ATF) in ServiceNow. ATF validates that deterministic configurations — business rules, flows, UI actions — behave exactly as expected after changes.
Agentic evaluation plays a similar governance role, but for probabilistic systems. Where ATF confirms “this step produces this exact outcome”, agentic evaluation confirms “this agent tends to behave correctly across defined scenarios.” In a way, it is the ATF for AI-driven logic — less about exact outputs, more about behavioural consistency within acceptable thresholds.
For mature adoption, I believe organisations should layer business-level KPIs on top. For example:
- Reduction in reassignment loops
- Average time to classify tickets or to resolve end to end.
- SLA adherence improvement
Out-of-the-box metrics validate execution. Business metrics will validate impact. Both are needed. It does not mean it will never surprise me.
Probabilistic systems do not offer certainty. They offer managed uncertainty.
Agentic evaluations are a tool for managing that uncertainty more systematically.




Leave a comment